Building a Production CAPTCHA-Solving Scraping Pipeline
Architecture guide for building a production-grade web scraping pipeline with integrated CAPTCHA solving — queues, retries, proxy rotation, and monitoring.
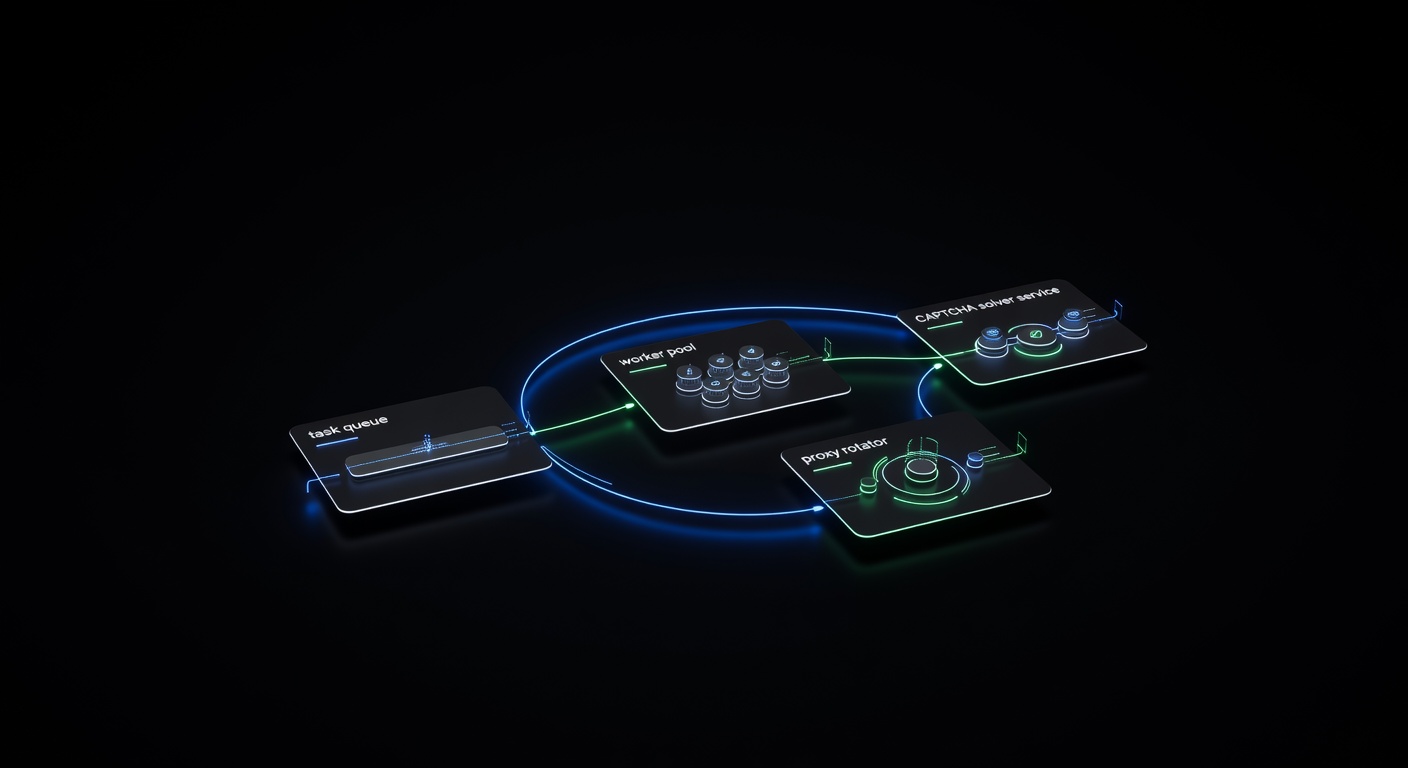
Building a production CAPTCHA-solving scraping pipeline means moving beyond single-threaded scripts to a system that handles failures, scales horizontally, and solves CAPTCHAs without human intervention. A well-designed pipeline separates URL management, page fetching, CAPTCHA solving, and data storage into distinct layers, each with its own retry logic and monitoring.
This guide covers the architecture of a production-grade pipeline, from task queues to CAPTCHA solver integration to alerting. For foundational CAPTCHA handling concepts, see the complete web scraping with CAPTCHA solving guide.
Pipeline Architecture
A production scraping pipeline separates concerns into five layers:
┌─────────────┐ ┌──────────────┐ ┌─────────────────┐
│ URL Queue │────▶│ Worker Pool │────▶│ Data Storage │
│ (Redis) │ │ (Scrapers) │ │ (PostgreSQL) │
└─────────────┘ └──────┬───────┘ └─────────────────┘
│
┌──────┴───────┐
│ Services │
├──────────────┤
│ CAPTCHA Solver│
│ Proxy Rotator │
│ Rate Limiter │
└──────────────┘
│
┌──────┴───────┐
│ Monitoring │
│ & Alerting │
└──────────────┘Each component has a clear responsibility:
- URL Queue holds pending scrape jobs with metadata (priority, retry count, assigned proxy).
- Worker Pool pulls jobs, fetches pages, and routes CAPTCHAs to the solver.
- CAPTCHA Solver communicates with the solving API and manages task polling.
- Proxy Rotator assigns proxies, tracks health, and removes failing IPs.
- Data Storage persists scraped data and job status.
- Monitoring tracks metrics and alerts on anomalies.
The Task Queue
Redis is the most common choice for scraping queues because it’s fast, supports sorted sets for priority ordering, and has built-in pub/sub for worker coordination.
import json
import redis
class ScrapeQueue:
def __init__(self, redis_url: str = "redis://localhost:6379"):
self.redis = redis.from_url(redis_url)
self.queue_key = "scrape:queue"
self.processing_key = "scrape:processing"
def add_urls(self, urls: list[dict], priority: int = 0):
pipe = self.redis.pipeline()
for url_data in urls:
job = json.dumps({
"url": url_data["url"],
"metadata": url_data.get("metadata", {}),
"retries": 0,
"max_retries": 3,
})
pipe.zadd(self.queue_key, {job: priority})
pipe.execute()
def get_next(self) -> dict | None:
result = self.redis.zpopmin(self.queue_key, count=1)
if not result:
return None
job_data, _ = result[0]
job = json.loads(job_data)
# Move to processing set with timestamp
self.redis.hset(self.processing_key, job["url"], job_data)
return job
def complete(self, url: str):
self.redis.hdel(self.processing_key, url)
def requeue(self, job: dict):
job["retries"] += 1
if job["retries"] < job["max_retries"]:
self.redis.zadd(self.queue_key, {json.dumps(job): job["retries"]})
else:
self.redis.sadd("scrape:dead_letter", json.dumps(job))The dead letter set captures jobs that have exhausted all retries, giving you visibility into persistent failures.
Worker Pool
Workers are the core of the pipeline. Each worker pulls a job from the queue, fetches the page, handles any CAPTCHAs, and stores the result.
import asyncio
import aiohttp
from concurrent.futures import ProcessPoolExecutor
class ScraperWorker:
def __init__(self, queue: ScrapeQueue, solver, proxy_pool, storage):
self.queue = queue
self.solver = solver
self.proxy_pool = proxy_pool
self.storage = storage
async def process_job(self, job: dict):
proxy = self.proxy_pool.get_proxy()
try:
html = await self.fetch_page(job["url"], proxy)
captcha = detect_captcha(html)
if captcha:
token = await self.solver.solve_async(captcha, job["url"])
html = await self.submit_with_token(
job["url"], token, captcha, proxy
)
data = self.parse(html, job["metadata"])
await self.storage.save(job["url"], data)
self.queue.complete(job["url"])
self.proxy_pool.mark_success(proxy)
except CaptchaSolveError:
self.queue.requeue(job)
except ProxyError:
self.proxy_pool.mark_failed(proxy)
self.queue.requeue(job)
except Exception as e:
logging.error(f"Unexpected error for {job['url']}: {e}")
self.queue.requeue(job)
async def run(self, concurrency: int = 10):
while True:
job = self.queue.get_next()
if job is None:
await asyncio.sleep(1)
continue
asyncio.create_task(self.process_job(job))Run multiple workers as separate processes or containers to scale horizontally.
CAPTCHA Solving Service
Wrap the solver API in a dedicated service with its own retry logic and concurrency limits:
import asyncio
import aiohttp
class CaptchaSolvingService:
def __init__(self, api_key: str, max_concurrent: int = 50):
self.api_key = api_key
self.base_url = "https://api.ucaptcha.net"
self.semaphore = asyncio.Semaphore(max_concurrent)
async def solve_async(self, captcha_info: dict, page_url: str) -> str:
async with self.semaphore:
async with aiohttp.ClientSession() as session:
# Create task
async with session.post(
f"{self.base_url}/createTask",
json={
"clientKey": self.api_key,
"task": {
"type": captcha_info["type"],
"websiteURL": page_url,
"websiteKey": captcha_info["key"],
},
},
) as resp:
data = await resp.json()
if data.get("errorId"):
raise CaptchaSolveError(data["errorDescription"])
task_id = data["taskId"]
# Poll with backoff
for attempt in range(24):
await asyncio.sleep(5)
async with session.post(
f"{self.base_url}/getTaskResult",
json={
"clientKey": self.api_key,
"taskId": task_id,
},
) as resp:
result = await resp.json()
if result["status"] == "ready":
return result["solution"]["gRecaptchaResponse"]
if result.get("errorId"):
raise CaptchaSolveError(result["errorDescription"])
raise CaptchaSolveError("Solve timed out after 120s")The semaphore limits concurrent CAPTCHA solve tasks, preventing you from overwhelming the API or exhausting your budget on a burst of requests.
Proxy Rotation Layer
The proxy rotator assigns proxies to requests, tracks their health, and removes failing ones from the pool:
import random
import time
from dataclasses import dataclass, field
@dataclass
class ProxyStats:
successes: int = 0
failures: int = 0
captchas: int = 0
last_used: float = 0
class ProxyPool:
def __init__(self, proxies: list[str]):
self.proxies = {p: ProxyStats() for p in proxies}
self.blacklist: set[str] = set()
def get_proxy(self) -> str:
available = [
p for p in self.proxies
if p not in self.blacklist
and time.time() - self.proxies[p].last_used > 2
]
if not available:
available = [p for p in self.proxies if p not in self.blacklist]
if not available:
raise ProxyError("No healthy proxies available")
proxy = random.choice(available)
self.proxies[proxy].last_used = time.time()
return proxy
def mark_success(self, proxy: str):
self.proxies[proxy].successes += 1
def mark_failed(self, proxy: str):
stats = self.proxies[proxy]
stats.failures += 1
if stats.failures > 5 and stats.failures / max(stats.successes, 1) > 0.5:
self.blacklist.add(proxy)
def mark_captcha(self, proxy: str):
self.proxies[proxy].captchas += 1The 2-second cooldown between uses of the same proxy distributes requests more evenly. Proxies with high failure rates get blacklisted automatically. For an in-depth look at proxy strategies, see our guide on proxies and CAPTCHA solving best practices.
Retry Strategy
Not all errors are equal. Classify them and apply different retry strategies:
| Error Type | Action | Max Retries |
|---|---|---|
| CAPTCHA detected | Solve and resubmit | 3 |
| CAPTCHA solve timeout | Requeue with delay | 2 |
| HTTP 429 (rate limited) | Requeue + switch proxy | 3 |
| HTTP 403 (blocked) | Switch proxy + requeue | 2 |
| HTTP 503 (server error) | Requeue with exponential backoff | 3 |
| Network timeout | Requeue immediately | 3 |
| Parse error | Send to dead letter queue | 0 |
Exponential backoff prevents your retries from compounding the problem:
def get_retry_delay(attempt: int, base: float = 2.0) -> float:
return base * (2 ** attempt) + random.uniform(0, 1)Monitoring and Alerting
A production pipeline needs real-time visibility into its health. Track these metrics:
Key Metrics
- Queue depth — how many URLs are waiting. Sustained growth means workers can’t keep up.
- CAPTCHA rate — percentage of requests that trigger CAPTCHAs. Rising rates suggest your anti-detection is degrading.
- Solve success rate — should stay above 95%. Drops indicate wrong site keys or API issues.
- Average solve time — typical is 10-30 seconds. Spikes suggest solver congestion.
- Proxy health — failure rates per proxy. Mass failures indicate an IP range ban.
- Throughput — pages scraped per minute.
- Error rate — percentage of jobs that fail and hit the dead letter queue.
Implementing Metrics Collection
import time
from collections import defaultdict
class PipelineMetrics:
def __init__(self):
self.counters = defaultdict(int)
self.timers = defaultdict(list)
def increment(self, name: str, value: int = 1):
self.counters[name] += value
def record_time(self, name: str, duration: float):
self.timers[name].append(duration)
def get_summary(self) -> dict:
summary = dict(self.counters)
for name, times in self.timers.items():
if times:
summary[f"{name}_avg"] = sum(times) / len(times)
summary[f"{name}_p95"] = sorted(times)[int(len(times) * 0.95)]
return summary
# Usage in worker
metrics = PipelineMetrics()
start = time.time()
token = await solver.solve_async(captcha, url)
metrics.record_time("captcha_solve", time.time() - start)
metrics.increment("captchas_solved")Alert Thresholds
Set alerts for:
- CAPTCHA rate above 40% (anti-detection is failing).
- Solve success rate below 90% (solver or parameters misconfigured).
- Queue depth growing for more than 10 minutes (workers are falling behind).
- Dead letter queue receiving more than 5% of total jobs (systemic failure).
Scaling the Pipeline
Horizontal Scaling
Run workers as containers (Docker/Kubernetes) and scale based on queue depth:
- Queue depth > 1000: Add workers.
- Queue depth < 100: Remove workers.
- CAPTCHA rate > 30%: Add proxies, not workers.
Cost Management
CAPTCHA solving is the primary variable cost. Reduce it by:
- Caching session cookies after a successful solve (most sites grant a grace period).
- Using the cheapest solver routing for non-time-sensitive tasks. uCaptcha’s routing presets (Cheapest, Fastest, Reliable) let you balance cost and speed per task.
- Batching URLs by domain so you can reuse sessions within each batch.
- Monitoring cost per page and setting budget caps per pipeline run.
Database Writes
Buffer writes to avoid overwhelming your database. Batch inserts every 100 records or every 5 seconds, whichever comes first:
class BufferedStorage:
def __init__(self, db, batch_size: int = 100, flush_interval: float = 5.0):
self.db = db
self.buffer = []
self.batch_size = batch_size
self.last_flush = time.time()
async def save(self, url: str, data: dict):
self.buffer.append({"url": url, "data": data})
if (len(self.buffer) >= self.batch_size
or time.time() - self.last_flush > self.flush_interval):
await self.flush()
async def flush(self):
if self.buffer:
await self.db.insert_many(self.buffer)
self.buffer.clear()
self.last_flush = time.time()Conclusion
A production scraping pipeline with CAPTCHA solving is a distributed system. The URL queue decouples job generation from execution, workers handle the messy reality of fetching and parsing, the CAPTCHA solving service abstracts solver API complexity, and the proxy rotator keeps your IPs healthy. Monitoring ties it all together by giving you visibility into what’s working and what isn’t.
uCaptcha fits into the solver service layer as a single API endpoint that routes tasks across CapSolver, 2Captcha, AntiCaptcha, CapMonster, and other providers. You don’t need to manage multiple solver accounts or implement failover logic — the platform handles provider selection, retries, and load distribution, letting your pipeline focus on scraping.
Related Articles
Proxies and CAPTCHA Solving: Best Practices for Scale
How to combine proxy rotation with CAPTCHA solving for large-scale automation — proxy types, when proxies help avoid CAPTCHAs, and when to use proxy vs proxyless task types.
 Pillar Guide
Pillar Guide
Web Scraping with CAPTCHA Solving: The Complete Guide
How to handle CAPTCHAs in web scraping pipelines — from detecting CAPTCHA types to integrating solver APIs, managing proxies, and building resilient scraping workflows.